易学性是什么?
易学性是其中之一可用性的五个质量组成部分(其他是效率、记忆、错误和满意度)。测试易学性对于用户频繁访问的复杂应用程序和系统特别有价值,尽管了解用户适应界面的速度对于即使是客观简单的系统也很有价值。
易学性考虑的是用户在第一次遇到界面时完成任务的容易程度,以及他们需要重复多少次才能高效完成任务。
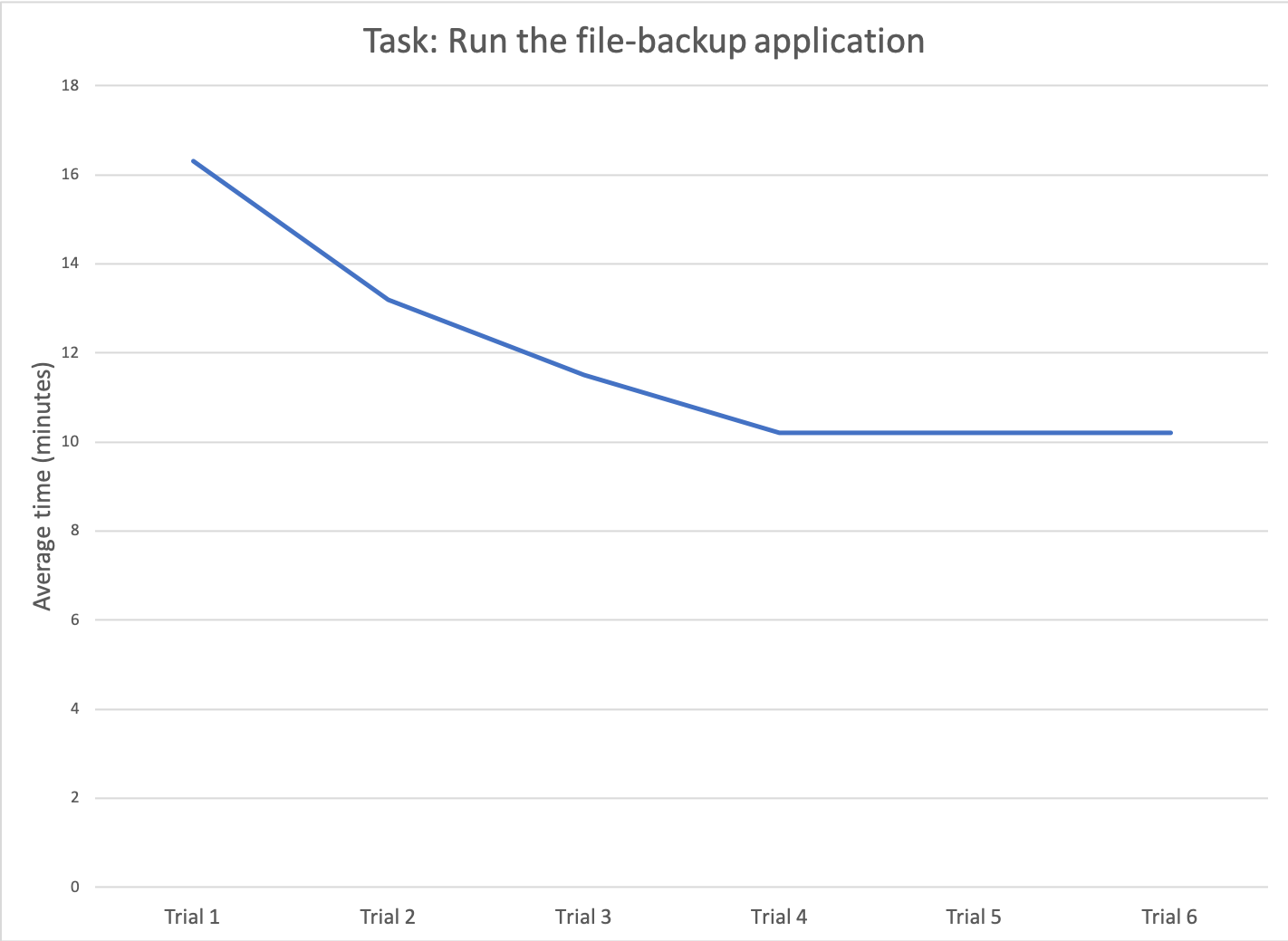
在易学性研究中,我们想要学习曲线,它揭示了人类行为的一个量化方面的纵向变化。根据学习曲线的数据,我们可以确定用户达到饱和需要多长时间——图表数据中的一个平台,告诉我们用户已经尽可能多地学习了界面。
例如,假设我们正在重新设计一个企业文件备份应用程序,打算由IT管理员定期运行。我们假设用户使用应用程序的频率足够高,他们将沿着学习曲线前进。对于这样的应用程序,用户能够尽快完成他们的工作是至关重要的。在这种情况下,学习性研究将决定管理员学习高效运行备份的速度。我们招募了几个有代表性的用户,并邀请他们到实验室。然后我们要求他们执行备份,并测量他们第一次执行备份所需的时间。接下来,我们让他们回到实验室,再做一遍,测量他们完成任务的时间。这个过程重复了几次。我们的研究结果将是一条学习曲线,它绘制了任务时间在一定数量的试验。
易学性和效率
易学性有三个不同的方面,每个方面对不同类型的用户都很重要:
- 首先使用核武器的易学性:当你第一次尝试时,使用这个设计是否容易?对于那些只执行一次任务的用户来说,易学性的这一方面很有趣。这些用户不会在学习曲线上进步,所以他们并不关心它看起来如何。
- 学习曲线的陡度:重复使用该设计,人们能多快变得更好?易学性的这一方面对于那些会多次使用设计的用户来说尤其重要,即使他们不会过度使用它。如果人们觉得他们正在进步,并且在使用你的系统方面变得越来越好,他们就会有动力坚持下去。(相反地,如果人们觉得情况几乎没有好转,无论他们如何努力,他们都会开始寻找更好的解决方案。)
- 效率的终极高原:一旦用户完全学会了如何使用这个界面,他们的生产力能达到多高?这方面对于经常和长期需要使用系统的人来说尤其重要——例如,当它是重要的日常任务的主要工具时。
当然,理想情况下,你的系统应该在这三个方面都运行良好。但是,在现实世界中,设计折衷常常是必要的,您应该塑造学习曲线,以主要迎合那些具有最高业务价值的用户。
这些维度的相对重要性还取决于用户生活中的阶段。新用户希望能够快速学习系统,并尽快达到最佳性能点(平台),但专家用户希望平台越低(即最佳任务时间越短)越好。
有时这些易学性的不同属性可能会把设计拉向不同的方向。例如,一个可学习的系统并不总是有效的.回到我们的示例,让我们假设备份是一步步执行的向导有很多说明和解释的工作流程。这个系统可能是高度可学习的:用户可能能够以尽可能快的速度执行任务,即使他们第一次完成它。但这条曲线将会非常平坦:他们第二次的速度不会快很多,因为他们需要通过同样的屏幕,回答同样的问题。随着用户对界面的熟练掌握,这种设计会让人感觉像是手把手的,重复使用时效率会很低。(正是出于这个原因,我们建议执行加速器,或过程快捷方式,供专业用户使用。)设计师必须小心地平衡易学性和效率。
为什么测量易学性?
高学习性有助于提高可用性。它导致了快速的系统入职,转化为低培训成本。此外,良好的学习性可以带来高满意度,因为用户会对他们的能力感到自信。
如果您的系统和相应的任务是复杂的,并且用户经常访问这些任务,那么您的产品可能是一个学习性研究的好例子.易学性研究是时间和预算消耗,所以不要随意地向利益相关者推销它们。对于用户不经常或只完成一次的任务(例如,注册服务或每年报税),衡量可学习性是没有意义的,因为用户很可能在每次遇到任务时都表现得像新用户。在这些情况下,一个标准可用性测试会比易学性研究更适合,更划算。
进行易学性研究
在易学性研究中,我们专注于收集指标,这就是为什么我们转向定量研究方法。这种研究需要集中的任务和控制实验,因此定量可用性测试最适合研究系统的易学性.
参与者
在进行这类研究时,我们试图确定人们学习我们的界面有多容易。因此,……很重要聚集那些几乎没有经验的参与者使用他们将要测试的系统。
在测试易学性时,需要考虑的一个因素是之前使用过类似系统的经验。先前的经验可能会帮助用户(例如,因为他们可能已经熟悉域约定),或者可能会减慢他们的速度(例如,因为他们可能会遭受改变厌恶).然而,这些数据仍然是有价值的,特别是当发布新产品的目标是从现有产品中窃取客户的时候。如果适用,招募没有类似系统经验的参与者和有类似系统经验的参与者,并计划比较两组的相应数据。
对于任何定量研究,我们建议你招募大量的参与者(通常至少30-40)。确切的数字取决于任务的复杂性,高度复杂的任务需要更多的参与者来考虑固有的更高的数据可变性,而简单的任务需要更少的参与者。
步骤1:确定度量
任务时间是易学性研究中最常用的收集指标.原因是学习幂律,即完成一项任务所需的时间随着任务重复次数的增加而减少。本文的其余部分将假设您将收集任务上的时间作为主要指标。
根据你的系统,任务时间可能并不相关,因此你需要一个不同的度量标准。在这些情况下,考虑收集错误的数量用户执行给定任务。
第二步:确定试验次数
下一步是决定收集这些指标的频率——每次收集数据的实例都被称为一次试验。
记住,我们要画出随时间变化的度规,所以我们需要相同的参与者多次完成相同的任务.我们建议您重复试验,直到达到稳定状态达成。一条平坦的曲线表明我们的参与者已经尽可能多地学习了系统(特定于这个任务)。
在考虑试验时,你可能会问两个问题:我应该进行多少次试验?试验的间隔应该有多远?这两个问题的答案取决于你的情况。
要预测用户达到饱和学习点所需的试验次数,请考虑系统的复杂性。作为起点,考虑5-10次试验,但当有疑问时,计划比你认为需要的更多的试验,有两个原因:(1)你想确保你已经达到了稳定的性能;(2)一旦你达到了稳定的性能,取消可用性会话通常比安排更多会话更容易。
如果你想知道两次试验之间需要多少时间,考虑一下你预期客户使用产品的频率,并尽可能地匹配这个间隔。对于用户每天或每周执行几次的任务,您可以在连续几天进行试验。但是对于一个月完成一次的任务,你可能需要间隔4周进行试验。
步骤3:收集和绘制数据
记得招募每次试验都有相同的参与者,并让他们在每次试验中完成相同的任务。(这与你想要的正常情况不同不同的测试用户学习不同的迭代设计。)您可能想要使用多个任务进行易学性研究和测试。如果是这种情况,一定要随机分配你的任务,以避免对结果产生偏见。在研究中,用户从一个任务中获取知识,并将其应用到未来的任务中;任务随机化有助于缓解这种影响。
对于每个任务,计算每次试验的公制平均数然后在线图上标上坐标轴。通过绘制每次试验的数据,您将获得该任务的学习曲线。
第四步:分析曲线
与任何定量研究一样,您将希望分析数据的统计意义。换句话说,你必须调查试验效果是否确实显著——也就是说,你在学习曲线上看到的下降是真实的,还是只是数据噪声的结果。通常,所涉及的统计方法相当简单——a单向重复测量方差分析以试验为因素。
一旦你完成了分析(并且大概发现了试验的效果是显著的),考虑一下大局:你学习曲线的斜率是多少?较难学习的界面在曲线上的下降相对较小,需要多次尝试才能达到饱和点。或者,高度可学习的系统具有陡峭的曲线,并在较少的重复后迅速下降并达到饱和点。
例如,在我们最初的文件备份示例中,用户尝试了4次才达到饱和并变得高效。这似乎是可以接受的。另一方面,如果他们花了30次试验才达到相同的水平,学习性可能就太低了。
同样,考虑最后的效率:一旦用户学会了如何执行任务,他们将花费10分钟,这是可以接受的吗?答案可能取决于竞争产品的这个数字是多少。如果竞争性分析不可行,你也可以将结果与成本和ROI.如果管理员每天最优执行备份任务的时间为10分钟,连续执行一年,即3650分钟(约60个小时)。以每小时100美元的成本计算,这意味着该公司将花费6000美元完成备份。这个数量是可以接受的还是需要降低(通过改进设计)将取决于每个产品的具体情况。
结论
产品的易学性告诉我们用户用该产品达到最佳行为的速度。对于使用相对频繁的ui,度量易学性是很重要的。易学性研究包括对完成相同任务的相同参与者进行重复测量。易学性研究的结果是一条学习曲线,它将揭示为了让用户有效地完成任务需要多少重复。
即使你没有进行一个完整的易学性研究项目来绘制完整的学习曲线,思考这些概念将帮助你做出权衡决定,以设计针对最重要客户的产品。
更多关于设计权衡的信息,如易学性与效率,请查看我们的课程,设计权衡和用户体验决策框架.
参考文献
汤姆·图利斯《比尔·艾伯特》(2013)测量用户体验:收集、分析和呈现可用性指标.摩根考夫曼。
艾伦·纽威尔,保罗·罗森布鲁姆(1980)。技能习得机制与实践规律.技术报告。卡内基梅隆大学计算机科学学院。




分享这篇文章: