网络是关于超链接的。但是,您可能想知道,当呈现一堆链接时,用户如何决定点击哪个链接,忽略哪个链接?答案是:信息香味。像食物香味指导动物到他们的饭菜一样,信息很香味指导人们对那些可能包含他们正在寻找的内容的网页。
信息气味是计算机科学中的一个中心概念信息觅食理论- 了解人们如何浏览网页和它们如何相互作用,以便满足某个问题或信息需要的信息不同的潜在来源理论是必不可少的。简单来说,它说的是,如果人们有一个问题,他们会决定去根据他们的(1)的可能性有多大,页面将提供一个回答他们的问题,和(2)如何估计其网页long it’s going to take to get the answer if they go to that page.
如果访问的话,页面将如何相关的估计值是该页面的信息量。
定义:信息香味相对于信息的信息(例如网页)的源代表用户的不完美估计源将从源的表示源自源的源。
信息气味是一个相对的概念,意思是同一个信息源可能有不同的信息气味,以满足不同的信息需求。例如,有标题的链接食物如果你在找奶酪,会有高信息气味,但如果你在找洗面奶,会有低信息气味。
您可能想知道信息来源代表什么以及它的表示可能是什么。在Web上,源通常是网页 - 最常由链接表示。当用户考虑是点击该链接,链接标签、链接所包含的内容、链接所处的环境以及用户可能掌握的关于来源的任何背景知识(包括来自他人的建议)都会影响信息气味该源发出的信息,因此该页面被访问或忽略的可能性。
在我们与食品觅食比喻,来源是食物patch-比方说,一个热带稀树草原。和萨凡纳的表现会是什么动物实际看到或感觉到 - 例如,视力或羚羊的气味。捕食者(像人)可能会考虑其它因素,如与大草原任何先前不好的经验(例如,难以狩猎的或用于与其他食肉动物猎物战斗的存储器中)与寻线,然后再继续。而且,即使它不进行,狩猎仍然可以证明,尽管所有的诱人线索不成功。
因此,这里有四个概念:实际的源(网页或大草原)及其远程表示(猎物的联系或视觉和嗅觉)。这有一个真价值(未知直到后消费,无论是阅读页面还是吃食物)和一个估计价值(评估前用于决定是继续点击还是捕猎)。

让我们来探索构成信息气味的每一个因素。
是什么弥补了信息香味
我们之前已经知道,信息气味有两大组成部分:用户看到了什么(由其他页面上的信息源的表示提供)给出)用户已经知道的关于源的信息。第一部分是由设计师在很大程度上控制:我们通常可以决定如何在页面将在另一个页面(如果其他网页的搜索引擎结果页面,虽然也许在较小的程度)来表示。第二个组件是仅间接通过可控设计师,通过感知价值他们可能已经在过去为该品牌或信息来源构建。
用户看到了什么
链接的标签
也许信息线索的最重要的组成部分,链接标签被认为是页面是关于什么的简明而准确的描述。如果这个描述感觉与用户相关的目标,链接将对用户和她的任务高信息线索,她将有可能点击它。
这是我们反复争论的主要原因链接名称应该是明确和自我解释的。如果链接名称过于模糊,模糊,人们可能会错过一个很好的信息来源。即使链接标签是精确和准确地描述它指向的网页,它仍然可能错过了标记,并具有较低的信息线索,如果它包含目标受众不容易理解的词语。Jargon,品牌的术语或简单太复杂的单词最终可能会被忽略,可能无法为所有用户提供足够的可理解性提示。

请注意。在用户体验中,我们经常使用短语“标签”(例如更多的或了解更多)信息气味低。”我们的意思是,不管你需要的信息是什么,都很难猜测这个链接会指向什么。我们有时也说“一个标签(例如消息)具有高度的信息气味”,当它准确而全面地描述了它导致的结果时。从技术上讲,第二种用法是不正确的——标签只会为那些寻找新闻的用户提供高信息气味,而为那些搜索其他东西的用户提供低信息气味。然而,即使对那些有不同信息需求的人来说,一个好的标签描述也是有用的,因为它节省了他们点击页面却发现它不是他们需要的东西的努力和失望。
伴随链接的内容
通常,在链接的旁边可能会有一个简短的文本片段或缩略图,目的是向用户提供附加信息。即使用户可能不会阅读与链接相关的所有文本,他们仍然可以浏览它并从中收集额外的线索。这些线索将增加该链接的信息气味。
这一事实有两大含义:
- 文章或页面的摘要文本应传达该信息源的要点并向链接标签添加详细信息。
一个糟糕的摘要是该网站的浪费机会,为用户浪费时间:该网站错过了机会告诉用户文章是否相关。正如您在上面的思科示例中看到的,标题摘要对标题中的模糊术语没有任何内容。
- 与链接相关联的图像应该总是描述性的,代表页面内容或它所代表的类别。
网站经常选择与页面内容关系不大的通用图像。

Sutterhealth.org:关联的图像查找步行护理和找到紧急护理是普通的,纯粹的装饰,不添加任何额外的线索到标签。然而,这些链接下的摘要文本确实解释了免预约护理和紧急护理之间的区别(并以蓝色显示关键词)。 但是,即使是选择一个相关的图像也并不总是足够好——尤其是当图像代表一个物体类别的时候。关于分类的学术文献(可以追溯到20世纪70年代埃莉诺·罗施(Eleanor Rosch)的研究)表明,一个类别中的所有成员并非生来平等。因此,人们将鸡的图像解释为鸟要比知更鸟的图像花费更长的时间,因为鸡在“鸟”类别中不如知更鸟具有代表性。所以,在为你的分类选择图片时,不要把美观或方便作为你的唯一标准。想想一个类别成员,它真正地说明了它所代表的对象的集合。

costco.com:选择代表该类别的图像咖啡和甜味剂几乎没有代表大多数人想到咖啡时的想法。因此,对于搜索该类别的用户,图像增加了很少的信息量(除非用户恰好寻找图像中所示的精确产品)。
链接出现的上下文
通常,页面上的其他内容也会影响链接被感知的方式(或者是否被看到)。例如,对于相同的信息需求,单词“Christmas”在两个不同的网站上可能有不同的信息气味,比如HarryandDavid.com和Williams-Sonoma.com。即使你以前从未听说过这些网站,如果你正在寻找圣诞餐桌的设置,Williams Sonoma的网站上气味会很浓,因为其他相关内容也在页面上可见,但Harry&David的网站上气味会很浓,原因相同。
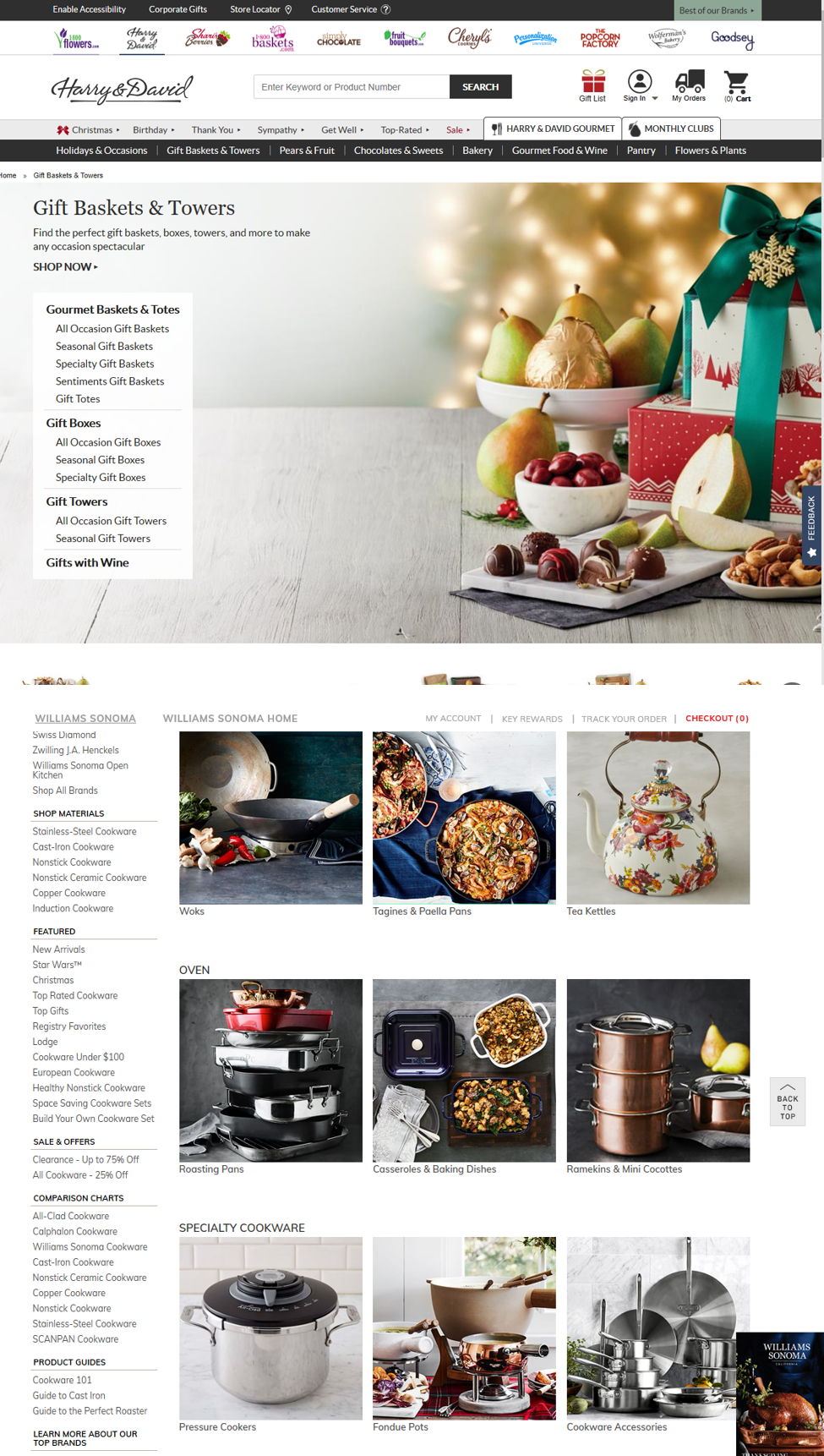
虽然情境通常是一个强有力的暗示,但设计师经常会犯过分依赖它的错误。特别是在小屏幕上,上下文并不总是完全可见的,或者可能会被忽略(可能是因为人们在搜索相关内容时快速滚动过它)。所以,最好是链接名称越具体越好,而不是依赖上下文提供额外的提示。

设计师制作的另一个常意错误不再提供足够的背景。我们经常看到带有非常小的文本和第一个屏幕上的大图像的着陆页。即使这些页面确实包含用户的正确信息,在许多情况下,它们也没有提供足够的上下文来告诉人们是否在正确的轨道上。因此,用户不会在搜索正确的信息中不再打扰滚动,也不会单击任何可见链接:他们很快决定该页面不值得探索,并简单地离开。因此,可以提供与站点链接的良好信息(例如,在搜索结果页面上)被实际页面提供的较差的上下文浪费在一起。

上下文还可以包括页面上的项目的位置。经常在右侧导轨中显示的信息可能被错误地作为广告解释,即使链接描述是足够的解释 - 只是因为人们已经知道广告是放在右边的页面,所以无论信息如何都会失败。
用户知道什么:用户的先前经验
信息香味的另一个组成部分是用户在过去积累的知识无论是直接 - 她自己以前的公司经验,内容相同,还有只需使用网络- 或间接地,从口腔或来自朋友或陌生人的建议书中。
以下是一些用户先验知识的组成部分:
熟悉品牌和信任。如果你已经知道威廉姆斯索诺玛,也许已经与之互动品牌之前,您将能够了解其网站上的“圣诞节”即使在没有其他页面上下文的情况下也是如此。或者,如果在过去您对思科进行了良好的体验,您也可以点击链接到其中一个产品,即使链接标签不是很描述。
熟悉域名。如果有人申请大学作为本科生,他可能知道公共数据集(包含大学发布的关于每年即将入学的本科生班级的统计数据)详细说明了考试成绩、gpa以及不同的录取标准等信息),通常都在大学网站的财务相关信息栏里。所以,对于这些人来说,链接标签财政部副校长办公室可能有高信息量,但对于首次听到公共数据的人来说,链接名称可能根本不透明。(并且既不是“常见数据集”本身的名称。因此,新手用户必须克服两级的差的信息香味,使其非常难以找到信息。)

社交觅食:来自他人的口口相传和推荐
的社会觅食理论这是信息搜集理论的延伸吗人们的网络是如何协同搜寻信息的。这些网络可以组织(例如,同样的问题一起工作的科学家的社区)或ad hoc(例如,维基百科的贡献者,在亚马逊评审,标注器协作标签系统上)。我们的想法是,随着人们寻找与信息或互动时,他们留下痕迹他人有关的各种信息源的质量。这些痕迹有效地增加其他用户的信息线索。
因此,让我们假设你正在亚马逊上寻找头发直发器。你选择一个,然后通读评论。一个广泛的评论说这个头发直发器很好,但不如另一个好。当你回到搜索结果页面时,你现在拥有的关于第二种产品的信息往往会让你倾向于点击它并考虑它,即使它比第一种产品更贵。这是因为这种产品现在带有额外的信息气味,由第一个直发器的评论者提供。

为什么点击诱饵在长期运行中不起作用
现在,您已经了解信息线索的不同组成部分,你可能会被诱惑到游戏他们为了吸引用户到你的网站,即使它可能不完全适合他们的需求。(这种方法通常通过驱动虚荣度量如点击次数。)
例如,您可能会诱惑提出一个有趣的标题,它与甚至没有远程连接到主题的无聊文章的时尚课题匹配。但这种方法可以反射。是的,您将收到您的点击,但与此同时,您将使用您的访问者的信任。就像在那个哭泣“狼”太多次数的男孩的故事中,下次当你真的有相关的内容时,人们将不太可能点击它,知道他们已经过去烧了。甚至更糟糕,虽然他们可能没有个人燃烧,但他们可能会从其他人经历的别人读取投诉。所以你甚至不一点击。
硬币的另一面是,如果你的品牌是强大的,人们可以信任你,你有错误(不是很多稍微更大的空间 - 很多错误最终会侵蚀你的品牌,因为品牌体验在互动媒体中)。但基本上,如果您可以增加用户在您的网站上找到所需的预期,那么,只要使用标签或图像,您将提供 - 然后人们将更有可能为您提供怀疑的好处偶尔的错误。




分享此文章: