收集可用性研究中的指标已成为一种常见的做法。我们经常建议,每当您报告此类指标时,您还包含相应的置信区间。但是什么是置信区间?
让我们绕个小弯子来理解什么是置信区间。为了做到这一点,让我们从新闻的一个例子开始,该报道称,根据一项民意调查,在2021年5月,79%的加拿大人要么已经接种了COVID-19疫苗,要么将尽快接种疫苗。
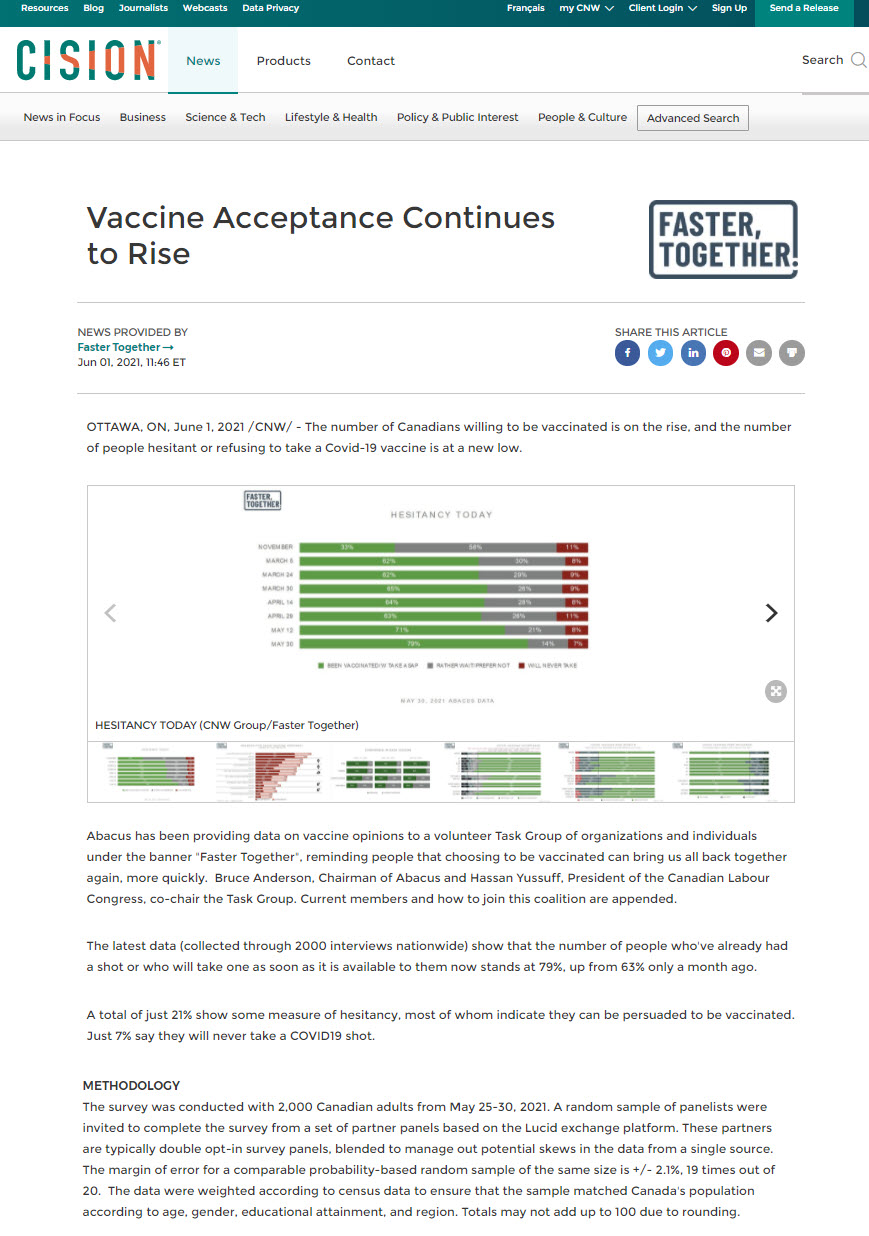
正如您可能知道的那样,这些文章中呈现的数字不是基于面试整个人口(即,所有加拿大成人)并从每个合格人员获得答案。相反,它们基于样本。在上面的新闻故事中,方法部分揭示了样品包括2000个加拿大成年人相同大小的可比概率随机样本的误差幅度为+/-2.1%,20次中有19次。
这句话是什么意思?
置信区间和错误边缘
即使您可能会难以了解句子中的一些单词,您可能猜测它的意义:79%+ / - 2%的成人加拿大人接种疫苗或愿意这样。我们恰恰不知道实际数量是否为78%或81%,但我们知道数字在某处为77%至81%。该范围是一个例子置信区间.
在其他地方,我们解释了真正分数理论;这是一个快速回顾。对于给定的指标(成为成功,任务的时间,错误的数量,或者在我们的示例中,无论有人愿意获得疫苗),我们都对整个人口的公制摘要感兴趣。那是所谓的真正的分数。不幸的是,除非我们有一个非常小的目标人群,否则无法衡量它的每个人,所以我们无法知道真正的得分。因此,我们估计通过查看我们的人口的样本。假设是我们从样本中获得的数字(所谓的观察得分)将预测真正的分数——我们整个人口的行为。误差幅度和置信区间告诉我们我们的预测有多好。
定义:A置信区间是您整个人口真正得分的可能范围。
请注意,置信区间和误差幅度传达了(几乎)相同的信息,通常只报告其中一个(就像本文开头的新闻故事)。如果有了误差范围和观察到的分数(通常是平均值),就可以很容易地计算出置信区间。事实上,置信区间的宽度是误差范围的两倍。

统计学是帮助我们计算置信区间的学科。取决于类型的度量您正在跟踪的(例如,用户体验中的成功率、时间、满意度),将有稍微不同的方法来计算置信区间。
在本文中,我们不会深入计算置信区间的细节。你很少需要手工计算置信区间——统计软件或网络计算器可以帮你做到。然而,我们需要对置信区间和影响置信区间的因素有一些基本的了解是很重要的。
置信区间越窄越好
假设在我们的一项量化可用性研究中,我们得到一个给定任务的成功率是40%,置信区间在0%到80%之间。这样的结果不是很有帮助,是吗?我们的用户群体中真正的成功率可能是10%,也可能是79%——这些数字对我们的UI来说是非常不同的。相比之下,如果我们对相同任务的置信区间在35%到45%之间,我们将获得更多关于界面的可用性以及人们完成任务的容易程度的信息。
一般来说,置信区间越窄,信息就越多。当我们进行定量研究时,我们总是努力缩小置信区间。
有三个因素通常影响置信区间的大小:
- 样本的大小:
- 样本的可变性
- 置信水平:您可以信任您的置信区间计算
第一个因素,样本大小(或者你的研究中包括了多少人),这就是为什么我们不建议您报告小定性研究的数字.样品大小越大,较窄的置信区间。当您的学习中只有几个人时,您的置信区间通常会很大,并且您所观察到的分数将是您一般人群行为的差的预测因素。
样本的可变性也会影响任务时间等连续指标的信心区间大小。如果你有一个任务,可以在许多不同的方式完成,一些快速和慢,和你的用户可能需要的路径,那么你的任务时间将完全不同于一个用户到另一个,你可能很难获得严格的置信区间,即便你在样本中包含许多参与者。一般来说,变异性越大,置信区间越宽。
让我们接下来讨论最后一个因素——信心水平。
置信水平
在置信区间的定义中,“可能”一词非常重要——置信区间是可能范围整个人口的真实分数。
置信区间计算是概率:这意味着,即使计算置信区间的统计方法通常会产生一个包含真实分数的范围,也无法绝对保证计算始终正确。您的计算可能会导致不包括真实分数的时间间隔。好消息是,你可以选择机会是什么,这是通过选择置信水平。
置信水平告诉您,您对置信区间的计算将包括真实得分的信心有多大。
不同的置信水平在计算置信区间的方式上略有不同,包含真实分数的几率也不同。例如,如果您的置信水平为95%,则表示95%的时间内,相应的置信区间将包括真实分数。或者,换句话说,如果你要进行100项研究,并根据这些研究中观察到的分数计算置信区间,那么在这100项研究中,有5项研究的置信区间是错误的,并且实际上不包含你人群的真实分数。或者,如果你进行20项研究,其中一项可能会得到错误的结果。(在其中19种情况下,你的计算是正确的——因此我们的示例句的最后一部分是正确的。)误差幅度[…]为+/-2.1%,20分中的19次。这是另一种说法,用于计算误差幅度的置信水平是95%。)
(是的,说“对应于95%置信水平的置信区间”是一口,所以它习惯于称为95%置信区间的间隔。与其他置信水平相同。)
对于科学出版物,置信度水平始终设置为95%。但在用户体验中,置信度不一定总是那么高。有时,您可能愿意承担更高的风险,即您的计算不正确。这取决于所起的作用。如果您正在为飞机仪表板设计界面,您可能希望对其具有较高的置信度降落飞机的成功率,因此您将使用高置信度。但是,如果您只是试图预测对您的业务不重要的任务的完成率(例如,可能在同一架飞机上重置乘客的视频系统),则较低的置信度可能是可以的。
你可能会问:为什么不总是有很高的置信水平?毕竟,更确定性总是更好,不是吗?不幸的是,高置信水平并非没有成本。更高的置信水平导致更宽的置信区间,而不是对应于较低置信水平的置信区间。例如,如果你对100人进行了一项研究,其中50人能够完成你的任务,那么95%的置信区间将是20%宽(从40%到60%),但80%的置信区间将只有12%宽(从44%到56%)。如果你想获得12%宽的95%置信区间,你需要再招募140名用户(总共240名研究参与者)这是一笔巨大的开支,在许多情况下都是合理的,但肯定不是所有情况下都是如此。

考虑一个较低的置信水平,好像它是一个滑雪者,更少的资源密集型计算。如果您投注5美元,您的完成率为44%和56%,那么花费大量资源可能没有意义,以获得95%的置信水平。你错了这不是一个很大的事。但是,如果您投注500万美元,那么您可能希望尽可能确定。(如果您投注数十亿美元,则错误的风险是不可接受的,您需要一个99%或更好的置信水平。但是,无论是最大的电子商务网站是否值得这在汇总中。)
结论
置信区间是一种统计工具,用于确定一项研究在多大程度上预测了整个人群的行为。一项研究得出的任何指标,无论是成功、任务时间、错误数量还是转换,都需要有相应的置信区间。
狭窄的置信区间携带更多信息,更可取,但通常需要更大的样本量。这就是为什么小型研究不可能代表整个用户群体的行为。
信心区间计算是概率性的,偶尔会出错,但出错的几率可以由研究人员控制。较高的置信度通常会得到正确的范围,但代价更高。研究人员可以根据利害关系和可用资源为他们的指标选择正确的信心水平。




分享此文章: